KNN Sınıflama
KNN (K-en Yakın Komşu) sınıflama, gözetimli öğrenme algoritmaları içerisinde yer alan ve sınıflandırma ile regresyon problemlerinde kullanılan basit ama etkili bir yöntemdir. Bu yöntemde, bir öğe sınıflandırılırken, veri setindeki en yakın 'k' komşusuna bakılır ve en yaygın sınıf bu öğeye atanır.
Kütüphanelerin Kaydedilmesi
Bu kısımda, KNN sınıflama modelinin uygulanması için gerekli olan kütüphaneler yüklenir. Bu kütüphaneler arasında veri seti işleme, model eğitimi, metrik hesaplama ve veri görselleştirme için gerekenler bulunmaktadır.
import matplotlib.pyplot as plt
from sklearn.datasets import load_wine
from sklearn.model_selection import train_test_split
import pandas as pd
from sklearn.metrics import classification_report, accuracy_score
from scipy import stats
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler, MinMaxScaler
from sklearn.model_selection import GridSearchCV
from sklearn.neighbors import KNeighborsClassifier
from sklearn.metrics import confusion_matrix
from sklearn.metrics import ConfusionMatrixDisplay
from sklearn.metrics import roc_curve
from sklearn.metrics import RocCurveDisplay
from sklearn.metrics import precision_recall_curve
from sklearn.metrics import PrecisionRecallDisplay
import sklearn.metrics as metrics
Veriyi Yükleme ve Ön İzleme Adımları
Bu aşamada, modelin eğitimi için kullanılacak veri seti yüklenir ve önizleme yapılır. Wine veri seti, farklı şarap örneklerine ait kimyasal özellikleri içerir ve bu örnekleri üç farklı sınıfa ayırır.
X, y = load_wine(return_X_y=True)
Veri setinin özellikleri ve sınıfları hakkında bilgi almak için:
print("Feature shape",X.shape)
print("Class shape",y.shape)
Feature shape (178, 13)
Class shape (178,)
Veri seti anahtarlarına erişim için:
load_wine().keys()
dict_keys(['data', 'target', 'frame', 'target_names', 'DESCR', 'feature_names'])
Tahmin edilen verilerin kategorik sınıflandırılması için:
print("Tahmin verileri kategorik sınıflandırılması:")
print(load_wine().target)
Tahmin verileri kategorik sınıflandırılması:
[0 0 0 0 0 0...2 2 2]
Veri seti hakkında detaylı bilgi için:
print("Veri seti özet bilgilendirilmesi")
print(load_wine().DESCR)
Veri seti özet bilgilendirilmesi
Wine recognition dataset... [Veri setinin detaylı açıklaması]
Özür dilerim, yanlışlık oldu. İşte düzeltilmiş halleriyle istediğiniz veriler:
Veri Ön İnceleme ve Temizleme Adımları
İlk beş satırı gözlemleyerek veri setinin yapısını ve özelliklerini inceleyebiliriz.
df_wine.head()
| alcohol | malic_acid | ash | alcalinity_of_ash | magnesium | total_phenols | flavanoids | nonflavanoid_phenols | proanthocyanins | color_intensity | hue | od280/od315_of_diluted_wines | proline |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 14.23 | 1.71 | 2.43 | 15.6 | 127 | 2.80 | 3.06 | 0.28 | 2.29 | 5.64 | 1.04 | 3.92 | 1065 |
| 13.20 | 1.78 | 2.14 | 11.2 | 100 | 2.65 | 2.76 | 0.26 | 1.28 | 4.38 | 1.05 | 3.40 | 1050 |
| 13.16 | 2.36 | 2.67 | 18.6 | 101 | 2.80 | 3.24 | 0.30 | 2.81 | 5.68 | 1.03 | 3.17 | 1185 |
| 14.37 | 1.95 | 2.50 | 16.8 | 113 | 3.85 | 3.49 | 0.24 | 2.18 | 7.80 | 0.86 | 3.45 | 1480 |
| 13.24 | 2.59 | 2.87 | 21.0 | 118 | 2.80 | 2.69 | 0.39 | 1.82 | 4.32 | 1.04 | 2.93 | 735 |
Veri Setinin Son On Satırının Gözlemi
Veri setinin son on satırını incelerken, veri setinin nasıl sonlandığı hakkında bilgi ediniriz.
df_wine.tail(10)
| alcohol | malic_acid | ash | alcalinity_of_ash | magnesium | total_phenols | flavanoids | nonflavanoid_phenols | proanthocyanins | color_intensity | hue | od280/od315_of_diluted_wines | proline |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 13.58 | 2.58 | 2.69 | 24.5 | 105 | 1.55 | 0.84 | 0.39 | 1.54 | 8.66 | 0.74 | 1.80 | 750 |
| 13.40 | 4.60 | 2.86 | 25.0 | 112 | 1.98 | 0.96 | 0.27 | 1.11 | 8.50 | 0.67 | 1.92 | 630 |
| 12.20 | 3.03 | 2.32 | 19.0 | 96 | 1.25 | 0.49 | 0.40 | 0.73 | 5.50 | 0.66 | 1.83 | 510 |
| 12.77 | 2.39 | 2.28 | 19.5 | 86 | 1.39 | 0.51 | 0.48 | 0.64 | 9.90 | 0.57 | 1.63 | 470 |
| 14.16 | 2.51 | 2.48 | 20.0 | 91 | 1.68 | 0.70 | 0.44 | 1.24 | 9.70 | 0.62 | 1.71 | 660 |
| 13.71 | 5.65 | 2.45 | 20.5 | 95 | 1.68 | 0.61 | 0.52 | 1.06 | 7.70 | 0.64 | 1.74 | 740 |
| 13.40 | 3.91 | 2.48 | 23.0 | 102 | 1.80 | 0.75 | 0.43 | 1.41 | 7.30 | 0.70 | 1.56 | 750 |
| 13.27 | 4.28 | 2.26 | 20.0 | 120 | 1.59 | 0.69 | 0.43 | 1.35 | 10.20 | 0.59 | 1.56 | 835 |
| 13.17 | 2.59 | 2.37 | 20.0 | 120 | 1.65 | 0.68 | 0.53 | 1.46 | 9.30 | 0.60 | 1.62 | 840 |
| 14.13 | 4.10 | 2.74 | 24.5 | 96 | 2.05 | 0.76 | 0.56 | 1.35 | 9.20 | 0.61 | 1.60 | 560 |
Eksik Değerlerin Kontrolü
Eksik değerlerin olup olmadığını kontrol ederiz, bu önemlidir çünkü eksik veriler analiz sonuçlarını etkileyebilir.
df_wine.isnull().sum()
| Column | Missing Values |
|---|---|
| alcohol | 0 |
| malic_acid | 0 |
| ash | 0 |
| alcalinity_of_ash | 0 |
| magnesium | 0 |
| total_phenols | 0 |
| flavanoids | 0 |
| nonflavanoid_phenols | 0 |
| proanthocyanins | 0 |
| color_intensity | 0 |
| hue | 0 |
| od280/od315_of_diluted_wines | 0 |
| proline | 0 |
df_wine.describe()
| alcohol | malic_acid | ash | alcalinity_of_ash | magnesium | total_phenols | flavanoids | nonflavanoid_phenols | proanthocyanins | color_intensity | hue | od280/od315_of_diluted_wines | proline | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| count | 178.000000 | 178.000000 | 178.000000 | 178.000000 | 178.000000 | 178.000000 | 178.000000 | 178.000000 | 178.000000 | 178.000000 | 178.000000 | 178.000000 | 178.000000 |
| mean | 13.000618 | 2.336348 | 2.366517 | 19.494944 | 99.741573 | 2.295112 | 2.029270 | 0.361854 | 1.590899 | 5.058090 | 0.957449 | 2.611685 | 746.893258 |
| std | 0.811827 | 1.117146 | 0.274344 | 3.339564 | 14.282484 | 0.625851 | 0.998859 | 0.124453 | 0.572359 | 2.318286 | 0.228572 | 0.709990 | 314.907474 |
| min | 11.030000 | 0.740000 | 1.360000 | 10.600000 | 70.000000 | 0.980000 | 0.340000 | 0.130000 | 0.410000 | 1.280000 | 0.480000 | 1.270000 | 278.000000 |
| 25% | 12.362500 | 1.602500 | 2.210000 | 17.200000 | 88.000000 | 1.742500 | 1.205000 | 0.270000 | 1.250000 | 3.220000 | 0.782500 | 1.937500 | 500.500000 |
| 50% | 13.050000 | 1.865000 | 2.360000 | 19.500000 | 98.000000 | 2.355000 | 2.135000 | 0.340000 | 1.555000 | 4.690000 | 0.965000 | 2.780000 | 673.500000 |
| 75% | 13.677500 | 3.082500 | 2.557500 | 21.500000 | 107.000000 | 2.800000 | 2.875000 | 0.437500 | 1.950000 | 6.200000 | 1.120000 | 3.170000 | 985.000000 |
| max | 14.830000 | 5.800000 | 3.230000 | 30.000000 | 162.000000 | 3.880000 | 5.080000 | 0.660000 | 3.580000 | 13.000000 | 1.710000 | 4.000000 | 1680.000000 |
Aykırı Değer Tespiti ve Temizlenmesi
Z-Skoru ile Aykırı Değer Tespiti:
Aykırı değerler, veri setinin genel dağılımından önemli ölçüde farklı olan veri noktalarıdır. Z-skoru yöntemi, her bir veri noktasının ortalamadan ne kadar standart sapma uzaklıkta olduğunu hesaplayarak bu aykırı değerleri belirler.
Aşağıdaki Python kodu, df_wine veri setindeki her bir özelliğin Z-skorunu hesaplar ve bu değerleri yazdırır. Ayrıca Z-skoru matrisinin boyutunu da verir.
z_score = np.abs(stats.zscore(df_wine))
print(z_score)
print("Z-skoru matrisinin boyutu:", len(z_score))
Aykırı Değerlerin Temizlenmesi:
Belirlenen eşik değerin (genellikle Z > 3) üzerindeki veri noktaları aykırı olarak kabul edilir ve bu noktalar veri setinden çıkarılır. Bu işlem, veri setini bu tür aşırı değerlerden arındırmak için yapılır.
Aşağıdaki Python kodu, aykırı değerleri tespit eder, bu değerlere sahip satırları çıkarır ve yeni veri setini new_df olarak oluşturur. Ayrıca, orijinal y etiketler dizisinden, çıkarılan satırlara karşılık gelen etiketleri de çıkararak y_new etiketler dizisini oluşturur.
outliers = list(set(np.where(z_score > 3)[0]))
new_df = df_wine.drop(outliers, axis=0).reset_index(drop=True)
display(new_df)
y_new = y[list(new_df.index)]
print("Yeni y veri setinin boyutu:", len(y_new))
Bu işlemler, veri setinden aykırı değerlerin başarıyla çıkarılmasını ve analiz veya model eğitimi için daha temiz bir veri setinin hazırlanmasını sağlar. Aykırı değerlerin çıkarılması, modelin genel performansını iyileştirebilir ve daha güvenilir sonuçlar elde edilmesine yardımcı olabilir.
| index | alcohol | malic_acid | ash | alcalinity_of_ash | magnesium | total_phenols | flavanoids | nonflavanoid_phenols | proanthocyanins | color_intensity | hue | od280/od315_of_diluted_wines | proline | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 14.23 | 1.71 | 2.43 | 15.6 | 127.0 | 2.80 | 3.06 | 0.28 | 2.29 | 5.64 | 1.04 | 3.92 | 1065.0 |
| 1 | 1 | 13.20 | 1.78 | 2.14 | 11.2 | 100.0 | 2.65 | 2.76 | 0.26 | 1.28 | 4.38 | 1.05 | 3.40 | 1050.0 |
| 2 | 2 | 13.16 | 2.36 | 2.67 | 18.6 | 101.0 | 2.80 | 3.24 | 0.30 | 2.81 | 5.68 | 1.03 | 3.17 | 1185.0 |
| 3 | 3 | 14.37 | 1.95 | 2.50 | 16.8 | 113.0 | 3.85 | 3.49 | 0.24 | 2.18 | 7.80 | 0.86 | 3.45 | 1480.0 |
| 4 | 4 | 13.24 | 2.59 | 2.87 | 21.0 | 118.0 | 2.80 | 2.69 | 0.39 | 1.82 | 4.32 | 1.04 | 2.93 | 735.0 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 163 | 173 | 13.71 | 5.65 | 2.45 | 20.5 | 95.0 | 1.68 | 0.61 | 0.52 | 1.06 | 7.70 | 0.64 | 1.74 | 740.0 |
| 164 | 174 | 13.40 | 3.91 | 2.48 | 23.0 | 102.0 | 1.80 | 0.75 | 0.43 | 1.41 | 7.30 | 0.70 | 1.56 | 750.0 |
| 165 | 175 | 13.27 | 4.28 | 2.26 | 20.0 | 120.0 | 1.59 | 0.69 | 0.43 | 1.35 | 10.20 | 0.59 | 1.56 | 835.0 |
| 166 | 176 | 13.17 | 2.59 | 2.37 | 20.0 | 120.0 | 1.65 | 0.68 | 0.53 | 1.46 | 9.30 | 0.60 | 1.62 | 840.0 |
| 167 | 177 | 14.13 | 4.10 | 2.74 | 24.5 | 96.0 | 2.05 | 0.76 | 0.56 | 1.35 | 9.20 | 0.61 | 1.60 | 560.0 |
Aykırı Değerlerin Çıkarılmasının Sonuçları
Aşağıdaki adımlar ve kodlar, aykırı değerlerin tespiti ve temizlenmesi sürecinin sonuçlarını göstermektedir:
Aykırı Değerlerin Tespiti ve Çıkarılması:
Aykırı değerlerin çıkarılmasının ardından, veri setinden çıkarılan satır sayısını gösteren bir çıktı:
print("Outlier değer içeren veri sayısı", len(df_wine) - len(new_df))Bu, veri setinden çıkarılan aykırı değer içeren satır sayısını verir. Örneğin:
Outlier değer içeren veri sayısı 10Bu örnekte, veri setinden 10 satırın aykırı değerler nedeniyle çıkarıldığı belirtilmiştir.
Yeni Veri Setinin Oluşturulması:
Aykırı değerler çıkarıldıktan sonra, aykırı olmayan verilerle yeni bir veri seti oluşturulur. Bu, modelleme veya daha fazla analiz için temiz bir başlangıç noktası sağlar:
X_wine = new_df.drop("index", axis=1)Bu işlem, aykırı değerler çıkarıldıktan sonra yeni oluşturulan veri setinden 'index' sütununun çıkarılmasını sağlar.
Yeni Veri Setinin Boyutunun Kontrolü:
Yeni veri setinin boyutunu kontrol etmek için:
print(len(X_wine))Bu, yeni veri setinin satır sayısını verir. Örneğin:
168Bu örnekte, yeni veri setinin 168 satır içerdiği belirtilmiştir, bu da orijinal veri setinden 10 satırın çıkarıldığını gösterir.
Yeni Veri Setinin İlk Beş Satırının Gösterilmesi:
Yeni veri setinin ilk beş satırını görmek için:
X_wine.head()Bu kod, temizlenmiş ve aykırı değerlerden arındırılmış yeni veri setinin ilk beş satırını gösterir. Bu, veri ön işlemenin nasıl gerçekleştiğini ve veri setinin son durumunu anlamak için yararlıdır.
| alcohol | malic_acid | ash | alcalinity_of_ash | magnesium | total_phenols | flavanoids | nonflavanoid_phenols | proanthocyanins | color_intensity | hue | od280/od315_of_diluted_wines | proline | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 14.23 | 1.71 | 2.43 | 15.6 | 127.0 | 2.80 | 3.06 | 0.28 | 2.29 | 5.64 | 1.04 | 3.92 | 1065.0 |
| 1 | 13.20 | 1.78 | 2.14 | 11.2 | 100.0 | 2.65 | 2.76 | 0.26 | 1.28 | 4.38 | 1.05 | 3.40 | 1050.0 |
| 2 | 13.16 | 2.36 | 2.67 | 18.6 | 101.0 | 2.80 | 3.24 | 0.30 | 2.81 | 5.68 | 1.03 | 3.17 | 1185.0 |
| 3 | 14.37 | 1.95 | 2.50 | 16.8 | 113.0 | 3.85 | 3.49 | 0.24 | 2.18 | 7.80 | 0.86 | 3.45 | 1480.0 |
| 4 | 13.24 | 2.59 | 2.87 | 21.0 | 118.0 | 2.80 | 2.69 | 0.39 | 1.82 | 4.32 | 1.04 | 2.93 | 735.0 |
Veride özellikle "Magnesium" ve "proline" değerlerinin veride çok aykırı olarak yüksek olduğu görülmektedir. Bu yüzden veride bir standartize etme adımı gerçekleştirilecektir!!!!!!
Normalize Edilmiş Verilerin İncelenmesi
Veri setindeki özelliklerin ölçeklendirilmesi, makine öğrenimi algoritmalarının daha iyi performans göstermesine yardımcı olabilir. Özellikle, birçok algoritma, tüm özelliklerin aynı ölçekte olmasını gerektirir. Bu nedenle, StandardScaler kullanılarak veri setinin özelliklerini ölçeklendirme işlemi gerçekleştirilmiştir.
Verilerin Standartlaştırılması:
StandardScaler kullanarak X_wine veri setinin tüm özelliklerini standartlaştırdık:
X_std = StandardScaler().fit_transform(X_wine)
Bu işlem, her bir özelliğin ortalamasını 0 ve standart sapmasını 1 olacak şekilde ayarlar.
Normalize Edilmiş Verilerin İncelenmesi:
Standartlaştırılmış verileri, anlaşılır bir formatta incelemek için pandas DataFrame'ine dönüştürdük:
df_onizleme = pd.DataFrame(X_std, columns=load_wine().feature_names)
df_onizleme.head()
Bu kod, standartlaştırılmış veri setinin ilk beş satırını gösterir. Burada, her bir özelliğin yeni değerlerinin nasıl dağıldığını ve standartlaştırma sonucunda elde edilen değerlerin özellikler arası karşılaştırılabilir hale nasıl getirildiğini görebiliriz.
Bu aşama, veri ön işleme sürecinin önemli bir parçasıdır ve makine öğrenimi modellerinin eğitimi için veri setini hazırlar.
| alcohol | malic_acid | ash | alcalinity_of_ash | magnesium | total_phenols | flavanoids | nonflavanoid_phenols | proanthocyanins | color_intensity | hue | od280/od315_of_diluted_wines | proline | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1.513539 | -0.578842 | 0.250637 | -1.209653 | 2.253466 | 0.840250 | 1.068668 | -0.669081 | 1.395565 | 0.233962 | 0.403766 | 1.857453 | 0.980537 |
| 1 | 0.210929 | -0.514888 | -0.945351 | -2.624711 | 0.097439 | 0.600640 | 0.763248 | -0.830933 | -0.517348 | -0.329398 | 0.449249 | 1.127605 | 0.933414 |
| 2 | 0.160342 | 0.015009 | 1.240421 | -0.244840 | 0.177292 | 0.840250 | 1.251920 | -0.507230 | 2.380432 | 0.251846 | 0.358284 | 0.804788 | 1.357515 |
| 3 | 1.690593 | -0.359574 | 0.539324 | -0.823728 | 1.135526 | 2.517517 | 1.506437 | -0.992784 | 1.187228 | 1.199721 | -0.414920 | 1.197783 | 2.284254 |
| 4 | 0.261516 | 0.225141 | 2.065240 | 0.527010 | 1.534790 | 0.840250 | 0.691983 | 0.221100 | 0.505398 | -0.356225 | 0.403766 | 0.467935 | -0.056154 |
Model Oluşturma İşlemleri
Bu bölümde, K-En Yakın Komşu (KNN) algoritması kullanılarak bir sınıflandırma modeli oluşturulmuştur. Ayrıca, modelin performansını artırmak için en uygun parametreler GridSearchCV kullanılarak belirlenmiştir.
Train_Test_Split
Veri seti, eğitim ve test olmak üzere iki bölüme ayrıldı. Bu bölme işlemi, modelin eğitiminde kullanılacak verileri ve modelin test edilmesinde kullanılacak verileri ayırmak için yapıldı.
X_train, X_test, y_train, y_test = train_test_split(X_std, y_new, test_size=0.3, random_state=42)
Eğitim ve test veri setlerinin boyutları:
- Eğitim verisi: 117 örnek, 13 özellik
- Test verisi: 51 örnek, 13 özellik
Grid Search ile En Uygun Parametrelerin Belirlenmesi
GridSearchCV kullanılarak KNN modeli için en uygun parametreler aranmıştır. Bu parametreler, modelin performansını maksimize etmek için önemlidir.
grid = {"weights": ["distance", "uniform"],
"algorithm": ["auto", "ball_tree", "kd_tree"],
"metric": ["manhattan", "chebyshev", "minkowski", "mahalanobis"],
"n_neighbors": np.arange(4, 10, 1)}
knn_cv = GridSearchCV(KNeighborsClassifier(), grid, cv=15)
knn_cv.fit(X_train, y_train)
En Uygun Parametreler
GridSearchCV sonucunda elde edilen en iyi parametreler ve skor:
- En iyi parametreler:
{'algorithm': 'auto', 'metric': 'manhattan', 'n_neighbors': 4, 'weights': 'distance'} - En iyi skor: 1.0
Default k Değeri ve En Uygun Parametreler ile KNN Modeli
Model, en uygun parametreler ile eğitilmiş ve eğitim ile test veri setleri üzerinde doğruluk skorları hesaplanmıştır:
- Eğitim seti doğruluk skoru: 1.0
- Test seti doğruluk skoru: 0.9607843137254902
Bu skorlar, modelin eğitim veri setine mükemmel şekilde uyduğunu ve test veri setinde de yüksek performans gösterdiğini belirtir.
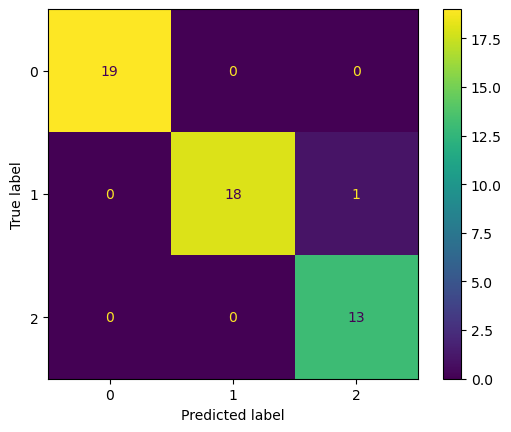
Karışıklık Matrisi
Modelin performansını daha iyi anlamak için karışıklık matrisi kullanılmıştır. Bu matris, modelin her sınıf için doğru ve yanlış tahminlerini gösterir. Örneğin, (0,1) ve (2,1) hücrelerindeki değerler, modelin bu sınıflarda yaptığı hatalı tahminlerin sayısını belirtir.
En Uygun K Değerinin Belirlenmesi
Modelin performansını farklı k değerleri için değerlendirerek en uygun k değerinin bulunması işlemi gerçekleştirilmiştir. Bu işlem, farklı k değerleri için ortalama hata oranlarının hesaplanmasını içerir ve en düşük hata oranına sahip k değeri, model için en uygun k değeri olarak seçilir. Bu örnekte, en düşük hata oranını veren k değeri 8 olarak belirlenmiştir.
En Uygun k Değeri ve Parametreler ile Modelin Oluşturulması
Bu bölümde, K-En Yakın Komşu sınıflandırma algoritması kullanılarak bir model oluşturulmaktadır. Seçilen parametrelerle model eğitilmiş ve test edilmiştir.
Model, 8 komşu kullanarak, 'manhattan' metriğini ve 'distance' ağırlıklandırmasını temel alarak oluşturulmuştur:
model1 = KNeighborsClassifier(n_neighbors = 8, algorithm = "auto", metric="manhattan", weights = "distance")
model1.fit(X_train, y_train)
KNeighborsClassifier(metric='manhattan', n_neighbors=8, weights='distance')
Modelin eğitim ve test setlerindeki doğruluk skorları aşağıdaki gibidir:
print("Train set doğruluk skoru", model1.score(X_train, y_train))
print("Test set doğruluk skoru", model1.score(X_test, y_test))
Train set doğruluk skoru 1.0
Test set doğruluk skoru 0.9803921568627451
En uygun k değeri kullanılarak, modelin performansı iyileştirilmiş ve daha önceki modelden farklı olarak yanlış tahminler azaltılmıştır.
Modelin sınıflandırma performansını değerlendirmek için oluşturulan karmaşıklık matrisi aşağıdaki gibidir:
y_pred = model1.predict(X_test)
con_matrix = confusion_matrix(y_test, y_pred)
con_matrix_display = ConfusionMatrixDisplay(con_matrix).plot()
Model Doğruluk Parametrelerinin Belirlenmesi
Bu bölümde, modelin çeşitli doğruluk parametreleri üzerinden değerlendirilmesi yapılmaktadır:
print(classification_report(y_test, y_pred))
print("Model Accuracy", accuracy_score(y_test, y_pred))
Bu raporda modelin kesinlik, geri çağırma ve F1 skoru gibi önemli performans göstergeleri yer almaktadır. Model genel olarak yüksek bir doğrulukla sınıflandırma yapmaktadır.
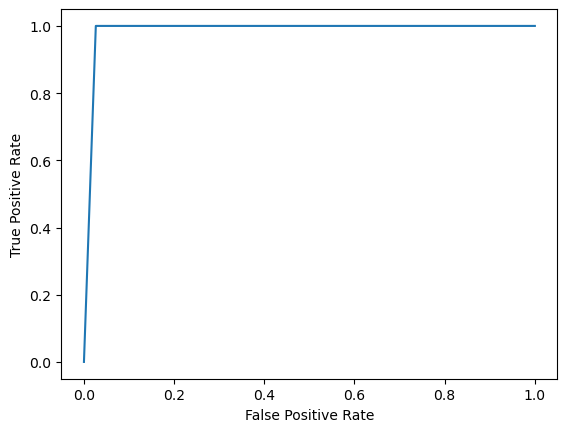
ROC-AUC Eğrisi
Modelin ROC-AUC eğrisi, sınıflandırıcının çeşitli eşik değerlerdeki performansını göstermektedir. ROC eğrisi, modelin duyarlılık (gerçek pozitif oranı) ve 1 - spesifisite (yanlış pozitif oranı) arasındaki ilişkiyi gösterir:
fpr, tpr, _ = roc_curve(y_test, y_pred, pos_label=2)
roc_display = RocCurveDisplay(fpr=fpr, tpr=tpr).plot()
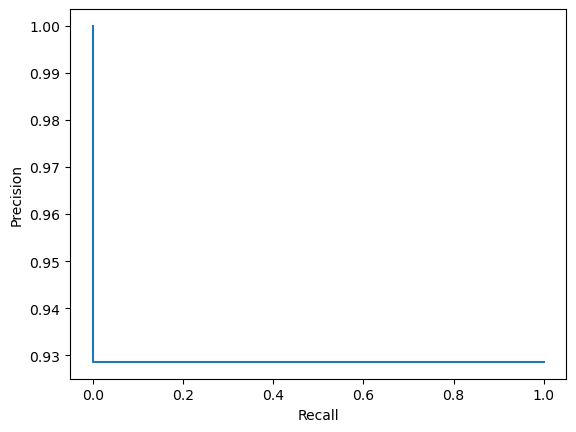
Precision Recall Eğrisi
Precision-Recall eğrisi, modelin farklı kesik noktalarındaki kesinlik ve geri çağırma değerlerini gösterir. Bu, özellikle dengesiz veri setlerinde kullanışlı bir metriktir:
prec, recall, _ = precision_recall_curve(y_test, y_pred, pos_label=2)
pr_display = PrecisionRecallDisplay(precision=prec, recall=recall).plot()
Veri Yükleme ve İlk Bakış
Bu bölümde, veri seti Python'a yüklenir ve veri setinin bir ön izlemesi yapılır:
import pandas as pd
data = pd.read_csv("./mxmh_survey_results.csv")
df = pd.DataFrame(data)
Veri setinin ilk beş satırını göstermek için kullanılır:
df.head(5)
| Timestamp | Age | Primary streaming service | Hours per day | While working | Instrumentalist | Composer | Fav genre | Exploratory | Foreign languages | ... | Frequency [R&B] | Frequency [Rap] | Frequency [Rock] | Frequency [Video game music] | Anxiety | Depression | Insomnia | OCD | Music effects | Permissions | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 8/27/2022 19:29:02 | 18.0 | Spotify | 3.0 | Yes | Yes | Yes | Latin | Yes | Yes | ... | Sometimes | Very frequently | Never | Sometimes | 3.0 | 0.0 | 1.0 | 0.0 | NaN | I understand. |
| 1 | 8/27/2022 19:57:31 | 63.0 | Pandora | 1.5 | Yes | No | No | Rock | Yes | No | ... | Sometimes | Rarely | Very frequently | Rarely | 7.0 | 2.0 | 2.0 | 1.0 | NaN | I understand. |
| 2 | 8/27/2022 21:28:18 | 18.0 | Spotify | 4.0 | No | No | No | Video game music | No | Yes | ... | Never | Rarely | Rarely | Very frequently | 7.0 | 7.0 | 10.0 | 2.0 | No effect | I understand. |
| 3 | 8/27/2022 21:40:40 | 61.0 | YouTube Music | 2.5 | Yes | No | Yes | Jazz | Yes | Yes | ... | Sometimes | Never | Never | Never | 9.0 | 7.0 | 3.0 | 3.0 | Improve | I understand. |
| 4 | 8/27/2022 21:54:47 | 18.0 | Spotify | 4.0 | Yes | No | No | R&B | Yes | No | ... | Very frequently | Very frequently | Never | Rarely | 7.0 | 2.0 | 5.0 | 9.0 | Improve | I understand. |
Bu bölümde, veri seti üzerinde çeşitli veri ön işleme adımları gerçekleştirilmektedir. Bu işlemler, veri setinin daha iyi anlaşılmasını ve modelleme aşaması için hazır hale getirilmesini sağlar.
Veri setinin sütunları ve veri türleri hakkında bilgi edinmek için aşağıdaki kod blokları kullanılır:
df.columns
Bu kod, veri setindeki tüm sütun isimlerini listeler.
df.info()
Bu kod, her bir sütun hakkında detaylı bilgi sağlar, örneğin sütunun veri türü ve kaç tane non-null değeri olduğu.
df.isnull().sum()
Bu kod, veri setindeki her bir sütun için eksik değerlerin (null) toplam sayısını hesaplar.
Veri setinden gereksiz veya istenmeyen sütunların çıkarılması için aşağıdaki kod kullanılır:
df = df.drop(["Timestamp", "BPM"], axis=1)
Bu kod, 'Timestamp' ve 'BPM' sütunlarını veri setinden çıkarır.
Veri setindeki kategorik değişkenleri belirlemek ve bunların listesini almak için aşağıdaki kod blokları kullanılır:
categorical = [var for var in df.columns if df[var].dtype == 'O']
print('There are {} categorical variables\n'.format(len(categorical)))
print('The categorical variables are :\n\n', categorical)
Bu kodlar, veri türü 'object' (yani kategorik) olan sütunları tespit eder ve bunları listeler.
Kategorik değişkenlerin ilk beş satırını görmek için aşağıdaki kod kullanılır:
df[categorical].head()
Bu kod, kategorik değişkenlerin ilk beş gözlemini gösterir, böylece bu değişkenlerin değerleri hakkında hızlıca bilgi edinilebilir.
| Primary streaming service | While working | Instrumentalist | Composer | Fav genre | Exploratory | Foreign languages | Frequency [Classical] | Frequency [Country] | Frequency [EDM] | ... | Frequency [Latin] | Frequency [Lofi] | Frequency [Metal] | Frequency [Pop] | Frequency [R&B] | Frequency [Rap] | Frequency [Rock] | Frequency [Video game music] | Music effects | Permissions | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | Spotify | Yes | Yes | Yes | Latin | Yes | Yes | Rarely | Never | Rarely | ... | Very frequently | Rarely | Never | Very frequently | Sometimes | Very frequently | Never | Sometimes | NaN | I understand. |
| 1 | Pandora | Yes | No | No | Rock | Yes | No | Sometimes | Never | Never | ... | Sometimes | Rarely | Never | Sometimes | Sometimes | Rarely | Very frequently | Rarely | NaN | I understand. |
| 2 | Spotify | No | No | No | Video game music | No | Yes | Never | Never | Very frequently | ... | Never | Sometimes | Sometimes | Rarely | Never | Rarely | Rarely | Very frequently | No effect | I understand. |
| 3 | YouTube Music | Yes | No | Yes | Jazz | Yes | Yes | Sometimes | Never | Never | ... | Very frequently | Sometimes | Never | Sometimes | Sometimes | Never | Never | Never | Improve | I understand. |
| 4 | Spotify | Yes | No | No | R&B | Yes | No | Never | Never | Rarely | ... | Sometimes | Sometimes | Never | Sometimes | Very frequently | Very frequently | Never | Rarely | Improve | I understand. |
df[categorical].isnull().sum()
Kategorik veriler incelendiğinde genellikle yes-no soruları ve "Never, Rarely, Sometimes, Very frequently" ile müzik çeşitlerinin dinlenme frekans dağılımları verilmiştir.
for var in categorical:
print("*"*25)
print(var)
print("-"*25)
print(df[var].value_counts())
for var in categorical:
print(var, ' İçerir ', len(df[var].unique()), ' etiketleri')
df["Primary streaming service"].value_counts()
En fazla ve farklı etikete sahip grup. Veri setinden çıkarabilirim çünkü spotify biraz baskın gözüküyor.
clear_categ = []
for col in categorical:
if df[col].isnull().mean()>0:
clear_categ.append(col)
print(col, (df[col].isnull().mean()))
print(clear_categ)
for i in clear_categ:
df[i].fillna(df[i].mode()[0],inplace=True)
O özelliğin ortalama değeri ile NaN değerlerin yerini doldurduk
df[categorical].isnull().sum()
df[categorical].head(5)
| Primary streaming service | While working | Instrumentalist | Composer | Fav genre | Exploratory | Foreign languages | Frequency [Classical] | Frequency [Country] | Frequency [EDM] | ... | Frequency [Latin] | Frequency [Lofi] | Frequency [Metal] | Frequency [Pop] | Frequency [R&B] | Frequency [Rap] | Frequency [Rock] | Frequency [Video game music] | Music effects | Permissions | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | Spotify | Yes | Yes | Yes | Latin | Yes | Yes | Rarely | Never | Rarely | ... | Very frequently | Rarely | Never | Very frequently | Sometimes | Very frequently | Never | Sometimes | Improve | I understand. |
| 1 | Pandora | Yes | No | No | Rock | Yes | No | Sometimes | Never | Never | ... | Sometimes | Rarely | Never | Sometimes | Sometimes | Rarely | Very frequently | Rarely | Improve | I understand. |
| 2 | Spotify | No | No | No | Video game music | No | Yes | Never | Never | Very frequently | ... | Never | Sometimes | Sometimes | Rarely | Never | Rarely | Rarely | Very frequently | No effect | I understand. |
| 3 | YouTube Music | Yes | No | Yes | Jazz | Yes | Yes | Sometimes | Never | Never | ... | Very frequently | Sometimes | Never | Sometimes | Sometimes | Never | Never | Never | Improve | I understand. |
| 4 | Spotify | Yes | No | No | R&B | Yes | No | Never | Never | Rarely | ... | Sometimes | Sometimes | Never | Sometimes | Very frequently | Very frequently | Never | Rarely | Improve | I understand. |
Bu bölümde, veri setindeki nümerik değişkenlerin işlenmesi ve kategorik değişkenlerin kodlanması işlemleri gerçekleştirilmektedir.
Öncelikle veri setindeki nümerik değişkenler belirlenir:
numerical = [var for var in df.columns if df[var].dtype != 'O']
print('-{}- Adet nümerik değişken vardır\n'.format(len(numerical)))
print('Bu Nümerik veriler :', numerical)
-6- Adet nümerik değişken vardır
Bu Nümerik veriler : ['Age', 'Hours per day', 'Anxiety', 'Depression', 'Insomnia', 'OCD']
Nümerik değişkenlerin ilk beş satırı gösterilmiştir ve her biri farklı psikolojik ve yaşam tarzı ölçütlerini temsil etmektedir.
Daha sonra, bu nümerik değişkenler içinde eksik değerlerin olup olmadığı kontrol edilir:
df[numerical].isnull().sum()
Sadece 'Age' sütununda bir eksik değer bulunduğu belirlenmiş ve bu değer, yaş ortalaması ile doldurulmuştur:
df["Age"].fillna(int(df["Age"].mean()), inplace=True)
Böylece, tüm nümerik değişkenlerde eksik değer kalmamıştır:
df[numerical].isnull().sum()
Ardından, 'Fav genre' yani en sevilen müzik türüne ilişkin benzersiz değerler incelenmiştir:
df["Fav genre"].unique()
Bu, çeşitli müzik türlerini içeren bir sütundur.
Daha sonra, bağımsız değişkenler (X) ve bağımlı değişken (Y) olarak ayrılır:
X, Y = df.drop(["Fav genre"], axis=1), df["Fav genre"]
Kategorik değişkenler, makine öğrenimi modellerinde kullanılmak üzere sayısal değerlere dönüştürülmektedir:
import category_encoders as ce
categorical = [var for var in df.columns if df[var].dtype == 'O']
categorical.remove("Fav genre")
encoder = ce.OrdinalEncoder(cols=categorical)
X = encoder.fit_transform(X)
Bu işlemler sonrasında, veri seti modelleme aşaması için hazır hale gelmiştir ve X kısmı, kategorik değişkenlerin kodlanmış haliyle güncellenmiştir:
X.head()
| Age | Primary streaming service | Hours per day | While working | Instrumentalist | Composer | Exploratory | Foreign languages | Frequency [Classical] | Frequency [Country] | ... | Frequency [R&B] | Frequency [Rap] | Frequency [Rock] | Frequency [Video game music] | Anxiety | Depression | Insomnia | OCD | Music effects | Permissions | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 18.0 | 1 | 3.0 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | ... | 1 | 1 | 1 | 1 | 3.0 | 0.0 | 1.0 | 0.0 | 1 | 1 |
| 1 | 63.0 | 2 | 1.5 | 1 | 2 | 2 | 1 | 2 | 2 | 1 | ... | 1 | 2 | 2 | 2 | 7.0 | 2.0 | 2.0 | 1.0 | 1 | 1 |
| 2 | 18.0 | 1 | 4.0 | 2 | 2 | 2 | 2 | 1 | 3 | 1 | ... | 2 | 2 | 3 | 3 | 7.0 | 7.0 | 10.0 | 2.0 | 2 | 1 |
| 3 | 61.0 | 3 | 2.5 | 1 | 2 | 1 | 1 | 1 | 2 | 1 | ... | 1 | 3 | 1 | 4 | 9.0 | 7.0 | 3.0 | 3.0 | 1 | 1 |
| 4 | 18.0 | 1 | 4.0 | 1 | 2 | 2 | 1 | 2 | 3 | 1 | ... | 3 | 1 | 1 | 2 | 7.0 | 2.0 | 5.0 | 9.0 | 1 | 1 |
Bu bölümde, veri seti üzerinde bir sınıflandırma modeli oluşturulmuş ve bu modelin performansı değerlendirilmiştir.
Öncelikle, bağımsız değişkenlerin ölçeklendirilmesi işlemi gerçekleştirilmiştir:
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
X = scaler.fit_transform(X)
Bu, veri setindeki tüm nümerik değişkenlerin standart bir ölçeğe dönüştürülmesini sağlar, böylece model daha iyi bir performans gösterebilir.
Y.head() kullanılarak bağımlı değişkenin (müzik türleri) ilk beş değeri gösterilmiştir:
0 Latin
1 Rock
2 Video game music
3 Jazz
4 R&B
Name: Fav genre, dtype: object
Veri seti, modelin eğitilmesi ve test edilmesi için eğitim ve test setlerine ayrılmıştır:
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, Y, test_size=0.3, random_state=0, stratify=Y)
Model olarak Gaussian Naive Bayes kullanılmış ve eğitim seti üzerinde eğitilmiştir:
from sklearn.naive_bayes import GaussianNB
gnb = GaussianNB()
gnb.fit(X_train, y_train)
Modelin test seti üzerindeki tahminleri ve doğruluk puanı aşağıdaki gibidir:
y_pred = gnb.predict(X_test)
from sklearn.metrics import accuracy_score
print('Model accuracy score: {0:0.4f}'.format(accuracy_score(y_test, y_pred)))
Model accuracy score: 0.4615
Bu, modelin %46.15 doğrulukla tahmin yaptığını gösterir.
Ayrıca, modelin çapraz doğrulama skorları da hesaplanmıştır:
from sklearn.model_selection import cross_val_score
cross_val_score(gnb, X_train, y_train, scoring='accuracy', cv=10)
Karmaşıklık matrisi ile modelin performansının detaylı analizi yapılmıştır:
import seaborn as sns
from sklearn.metrics import classification_report, confusion_matrix, accuracy_score, roc_curve, roc_auc_score
import matplotlib.pyplot as plt
import numpy as np
y_pred = gnb.predict(X_test)
conf_mat = confusion_matrix(y_test, y_pred)
classes = Y.unique()
f, ax = plt.subplots(figsize=(15, 15))
sns.heatmap(conf_mat, annot=True, fmt='.0f')
ax.set_xticklabels(classes)
ax.set_yticklabels(classes)
plt.show()
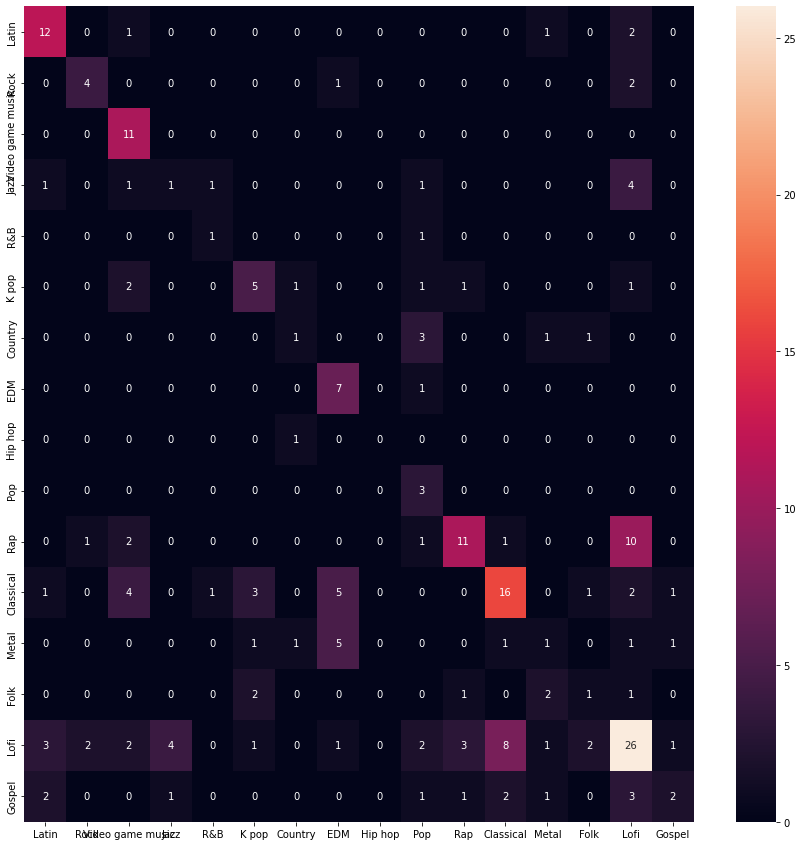
Bu matris, farklı müzik türleri arasında modelin nasıl performans gösterdiğini gösterir.
Son olarak, modelin sınıflandırma raporu incelenmiştir:
classification_report = classification_report(y_test, y_pred)
print(classification_report)
Bu rapor, modelin her bir sınıf için kesinlik, geri çağırma ve F1 skoru gibi metriklerini içerir. Bu değerler, modelin her bir müzik türüne ne kadar iyi tahmin yaptığını gösterir.